Measuring the interactions of species with GloBI

Yikang Li
I am Yikang Li, an international student from Tianjin, China. I recently just graduated from UC Berkeley with BA degree in Statistics. I have long been interested in data science and therefore seized every possible means to be part of projects to improve my practical ability in data mining. This interest lead me to exploring Biodiversity Data with the Cabinet of Curiosity Team. During this research experience, I, together with other interns, studied different natural history databases and revised each other’s work using Github. During our first week togerther we all explored what types of data was available to us and together created a brief list with summaries of the databases we could find. We each were given the option to explore one database of our choosing (link). I choose Global Biotic Interactions (GLoBI) globalbioticinteractions.org, a database of biodiversity, which as the name implies, collates species interactions data from around the world.
GloBI does a fantastic job of explaining itself:
Global Biotic Interactions (GloBI) provides open access to species interaction data (e.g., predator-prey, pollinator-plant, pathogen-host, parasite-host) by combining existing open datasets using open source software. By providing an infrastructure to capture and share interaction data, individual biologists can focus on gathering new interaction data and analyzing existing datasets without having to spend resources on (re-) building a cyberinfrastructure to do so.
I was intitially interested in the GloBI database because it provides data in the format of interactions, which is different from other biodiversity databases. Instead of focusing on one species at a time, it connects different species by describing interactions between them. My work will be posted in two parts 1. Accessing and understanding the data 2. Exploring the data with network visualizations. Hope you enjoy!
How to access GloBi
To start, we must get the access the data! I will discuss a few options that I tried.
1. The R package rglobi
There is a package called rglobi in R which allows us to access the database on Global Biotic Interactions (GloBI). Here is a description from the documentation of the package:
A programmatic interface to the web service methods provided by Global Biotic Interactions (GloBI). GloBI provides access to spatial-temporal species interaction records from sources all over the world. rglobi provides methods to search species interactions by location, interaction type, and taxonomic name. In addition, it supports Cypher, a graph query language, to allow for executing custom queries on the GloBI aggregate species interaction data set.”
To use its methods and functions, we need to install and load the package “rglobi” in R.
install.packages("rglobi")
library(rglobi)
Users are able to search data on species interactions by location, interaction type, taxonomic names and so on. Please check out the rglobi vignette to learn more about the use of this package. While the R package provides built in methods and functions, it has limitation on the maximum amount of data displayed. Look into Pagination options to understand the limitations: https://github.com/ropensci/rglobi/blob/master/vignettes/rglobi_vignette.Rmd#L410
By default, the amount of results are limited. If you’d like to retrieve all results, you can used pagination. For instance, to retrieve parasitic interactions using pagination, you can use:
otherkeys = list("limit"=10, "skip"=0)
first_page_of_ten <- get_interactions_by_type(interactiontype = c("hasParasite"), otherkeys = otherkeys)
otherkeys = list("limit"=10, "skip"=10)
second_page_of_ten <- get_interactions_by_type(interactiontype = c("hasParasite"), otherkeys = otherkeys)
Basically you have to exhaust all available interactions, you can keep paging results until the size of the page is less than the limit (e.g., nrows(interactions) < limit).
2. GloBI API
Another way to access the GloBI data is through the API: https://github.com/jhpoelen/eol-globi-data/wiki/API. The link above contains the API which provide access to interaction data for the purpose of integrating the data into wikis, custom webpages or other interaction exploration tools.
3. Download Everything
The third option is to download the whole dataset directly at https://www.globalbioticinteractions.org/data. Datasets are available to download in different formats including tsv, csv and N-Quads/RDF. I chose the .tsv version.
Basic data exploration and characteristics
I ended up choosing Choice 3 and explored the dataset with Python in the Jupyter notebook enviroment. One of the reasons is that I don’t want to be limited by the built-in functions in rglobi package. Importing the whole dataset allows me to explore in whatever ways I want to. Also, by Choice 3, I have the same dataset everytime so the results can be fully reproducible.
If you would like to follow along to follow along in a Jupyter notebook, please checkout the notebook here: Notebook. You will first need to download the interactions.tsv file here: interactions.tsv.gz.
%matplotlib inline
import pandas as pd
# Takes a few mintutes to load.
# If following along please download and unzip interactions.tsv.gz from
# https://depot.globalbioticinteractions.org/snapshot/target/data/tsv/interactions.tsv.gz
# Unziping the file is ~6.5 GB
# Don't forget to change path to the file on your computer
data = pd.read_csv('~/Desktop/interactions.tsv', delimiter='\t', encoding='utf-8')
/anaconda3/lib/python3.7/site-packages/IPython/core/interactiveshell.py:3020: DtypeWarning: Columns (21,22,23,24,25,26,27,28,29,30,41,42,43,44,45,46,47,48,49,50,55,58,59,60,61,62,63,64,65,68,69,72,73,78) have mixed types. Specify dtype option on import or set low_memory=False.
interactivity=interactivity, compiler=compiler, result=result)
# See the first few rows
data.head()
| sourceTaxonId | sourceTaxonIds | sourceTaxonName | sourceTaxonRank | sourceTaxonPathNames | sourceTaxonPathIds | sourceTaxonPathRankNames | sourceTaxonSpeciesName | sourceTaxonSpeciesId | sourceTaxonGenusName | ... | eventDateUnixEpoch | argumentTypeId | referenceCitation | referenceDoi | referenceUrl | sourceCitation | sourceNamespace | sourceArchiveURI | sourceDOI | sourceLastSeenAtUnixEpoch | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | EOL:4472733 | EOL:4472733 | EOL:4472733 | Deinosuchus | genus | Deinosuchus | EOL:4472733 | genus | NaN | NaN | Deinosuchus | ... | NaN | https://en.wiktionary.org/wiki/support | Rivera-Sylva H.E., E. Frey and J.R. Guzmán-Gui... | 10.4267/2042/28152 | NaN | Katja Schulz. 2015. Information about dinosaur... | KatjaSchulz/dinosaur-biotic-interactions | https://github.com/KatjaSchulz/dinosaur-biotic... | NaN | 2018-12-14T23:59:22.189Z |
| 1 | EOL:4433651 | EOL:4433651 | EOL:4433651 | Daspletosaurus | genus | Daspletosaurus | EOL:4433651 | genus | NaN | NaN | Daspletosaurus | ... | NaN | https://en.wiktionary.org/wiki/support | doi:10.1666/0022-3360(2001)075<0401:GCFACT>2.0... | 10.1666/0022-3360(2001)075<0401:GCFACT>2.0.CO;2 | NaN | Katja Schulz. 2015. Information about dinosaur... | KatjaSchulz/dinosaur-biotic-interactions | https://github.com/KatjaSchulz/dinosaur-biotic... | NaN | 2018-12-14T23:59:22.189Z |
| 2 | EOL_V2:24210058 | EOL_V2:24210058 | OTT:3617018 | GBIF:4975216 |... | Repenomamus robustus | species | Eucarya | Opisthokonta | Metazoa | Eumetazoa |... | EOL:5610326 | EOL:2910700 | EOL:42196910 | EOL... | | | subkingdom | | | | | | | | | supe... | Repenomamus robustus | EOL_V2:24210058 | Repenomamus | ... | NaN | https://en.wiktionary.org/wiki/support | doi:10.1038/nature03102 | 10.1038/nature03102 | NaN | Katja Schulz. 2015. Information about dinosaur... | KatjaSchulz/dinosaur-biotic-interactions | https://github.com/KatjaSchulz/dinosaur-biotic... | NaN | 2018-12-14T23:59:22.189Z |
| 3 | EOL:4433892 | EOL:4433892 | EOL:4433892 | Sinocalliopteryx gigas | species | Sinocalliopteryx gigas | EOL:4433892 | species | Sinocalliopteryx gigas | EOL:4433892 | NaN | ... | NaN | https://en.wiktionary.org/wiki/support | doi:10.1371/journal.pone.0044012 | 10.1371/journal.pone.0044012 | NaN | Katja Schulz. 2015. Information about dinosaur... | KatjaSchulz/dinosaur-biotic-interactions | https://github.com/KatjaSchulz/dinosaur-biotic... | NaN | 2018-12-14T23:59:22.189Z |
| 4 | EOL:4433892 | EOL:4433892 | EOL:4433892 | Sinocalliopteryx gigas | species | Sinocalliopteryx gigas | EOL:4433892 | species | Sinocalliopteryx gigas | EOL:4433892 | NaN | ... | NaN | https://en.wiktionary.org/wiki/support | doi:10.1371/journal.pone.0044012 | 10.1371/journal.pone.0044012 | NaN | Katja Schulz. 2015. Information about dinosaur... | KatjaSchulz/dinosaur-biotic-interactions | https://github.com/KatjaSchulz/dinosaur-biotic... | NaN | 2018-12-14T23:59:22.189Z |
5 rows × 80 columns
# Check the number of rows
len(data)
3456395
# How many columns?
len(data.columns)
80
# What are the 80 columns of this dataset?
data.columns
Index(['sourceTaxonId', 'sourceTaxonIds', 'sourceTaxonName', 'sourceTaxonRank',
'sourceTaxonPathNames', 'sourceTaxonPathIds',
'sourceTaxonPathRankNames', 'sourceTaxonSpeciesName',
'sourceTaxonSpeciesId', 'sourceTaxonGenusName', 'sourceTaxonGenusId',
'sourceTaxonFamilyName', 'sourceTaxonFamilyId', 'sourceTaxonOrderName',
'sourceTaxonOrderId', 'sourceTaxonClassName', 'sourceTaxonClassId',
'sourceTaxonPhylumName', 'sourceTaxonPhylumId',
'sourceTaxonKingdomName', 'sourceTaxonKingdomId', 'sourceId',
'sourceOccurrenceId', 'sourceCatalogNumber', 'sourceBasisOfRecordId',
'sourceBasisOfRecordName', 'sourceLifeStageId', 'sourceLifeStageName',
'sourceBodyPartId', 'sourceBodyPartName', 'sourcePhysiologicalStateId',
'sourcePhysiologicalStateName', 'interactionTypeName',
'interactionTypeId', 'targetTaxonId', 'targetTaxonIds',
'targetTaxonName', 'targetTaxonRank', 'targetTaxonPathNames',
'targetTaxonPathIds', 'targetTaxonPathRankNames',
'targetTaxonSpeciesName', 'targetTaxonSpeciesId',
'targetTaxonGenusName', 'targetTaxonGenusId', 'targetTaxonFamilyName',
'targetTaxonFamilyId', 'targetTaxonOrderName', 'targetTaxonOrderId',
'targetTaxonClassName', 'targetTaxonClassId', 'targetTaxonPhylumName',
'targetTaxonPhylumId', 'targetTaxonKingdomName', 'targetTaxonKingdomId',
'targetId', 'targetOccurrenceId', 'targetCatalogNumber',
'targetBasisOfRecordId', 'targetBasisOfRecordName', 'targetLifeStageId',
'targetLifeStageName', 'targetBodyPartId', 'targetBodyPartName',
'targetPhysiologicalStateId', 'targetPhysiologicalStateName',
'decimalLatitude', 'decimalLongitude', 'localityId', 'localityName',
'eventDateUnixEpoch', 'argumentTypeId', 'referenceCitation',
'referenceDoi', 'referenceUrl', 'sourceCitation', 'sourceNamespace',
'sourceArchiveURI', 'sourceDOI', 'sourceLastSeenAtUnixEpoch'],
dtype='object')
How many different types of taxons as sources & target?
You can see that many of the columns start with either “source”, “target”. Columns in which start with “source” describe the organisms or group of organisms that act upon the “target” organism. These columns are different ways to describe those organisms. The TaxonIDs columns are columns that link the organisms to an established database of organisms such as the Encyclopedia of Life. The great part of these columns is that they are unique IDs.
Let’s check out how many unique organims or organims groups there are in GloBi.
# Source taxon
len(data['sourceTaxonId'].unique())
147510
#Target taxon
len(data['targetTaxonId'].unique())
106613
What interaction types are there?
The source and target organisms are connected by the action in which they interact and are described by the interaction columns which must fit into 37 interaction types.
data['interactionTypeName'].unique()
array(['eats', 'preysOn', 'interactsWith', 'pollinates', 'parasiteOf',
'pathogenOf', 'visitsFlowersOf', 'adjacentTo', 'dispersalVectorOf',
'hasHost', 'endoparasitoidOf', 'symbiontOf', 'endoparasiteOf',
'hasVector', 'ectoParasiteOf', 'vectorOf', 'livesOn', 'livesNear',
'parasitoidOf', 'guestOf', 'livesInsideOf', 'farms',
'ectoParasitoid', 'inhabits', 'kills', 'hasDispersalVector',
'livesUnder', 'kleptoparasiteOf', 'hostOf', 'eatenBy',
'flowersVisitedBy', 'preyedUponBy', 'hasParasite', 'pollinatedBy',
'visits', 'commensalistOf', 'hasPathogen'], dtype=object)
# number of different types of interaction
len(data['interactionTypeName'].unique())
37
Each record in GloBI comes from a specific dataset. One of the great parts of GloBI is the transparency on exactly where that data is coming from. GloBI has a system set up that continually gathers the information from its sources on a daily basis. Because of this, the database can fix a mistake on their end and without intervention GloBi will incorporate those changes into their data set. You can tell the source of the data from a few columns, but what is especially interesting is the sourceNamespace column which displays the exact place on GitHub where the data is coming from.
# Top 10 data sources ranked by amount of records contributed to GloBI
data['sourceNamespace'].value_counts().head(10)
globalbioticinteractions/fishbase 504260
globalbioticinteractions/arthropodEasyCaptureAMNH 350213
millerse/Wardeh-et-al.-2015 271904
globalbioticinteractions/natural-history-museum-london-interactions-bank 242429
millerse/Dapstrom-integrated-database-and-portal-for-fish-stomach-records 225564
globalbioticinteractions/ices 183935
EOL/pseudonitzchia 183773
globalbioticinteractions/noaa-reem 122328
millerse/US-National-Parasite-Collection 99713
globalbioticinteractions/roopnarine 96647
Name: sourceNamespace, dtype: int64
To look at where GloBI is getting this data from simply add the first column to github.com/.
Example: The largest contributer appears to be Fishbase github.com/globalbioticinteractions/fishbase. You can also get the status of GloBi’s interaction with the data sources here: https://www.globalbioticinteractions.org/status.html.
Many of the columns are related to the type of organism being described and the most intersting
I’m interested in how many unique interaction type records are found in GloBi. The most interesting columns and really the heart of the database is sourceTaxonId, interactionTypeName, and targetTaxonId. With these three columns you can see what an animal interacts with and how.
data[['sourceTaxonId', 'interactionTypeName', 'targetTaxonId', 'sourceTaxonName']].head(10)
| sourceTaxonId | interactionTypeName | targetTaxonId | sourceTaxonName | |
|---|---|---|---|---|
| 0 | EOL:4472733 | eats | EOL_V2:42417811 | Deinosuchus |
| 1 | EOL:4433651 | eats | EOL_V2:42417811 | Daspletosaurus |
| 2 | EOL_V2:24210058 | eats | EOL:4532049 | Repenomamus robustus |
| 3 | EOL:4433892 | eats | EOL_V2:4433896 | Sinocalliopteryx gigas |
| 4 | EOL:4433892 | eats | EOL:4433563 | Sinocalliopteryx gigas |
| 5 | EOL:4433551 | eats | EOL:42331729 | Microraptor gui |
| 6 | EOL:4531246 | eats | EOL_V2:4530741 | Baryonyx walkeri |
| 7 | EOL:4531246 | eats | EOL:4653801 | Baryonyx walkeri |
| 8 | EOL:4433582 | eats | EOL_V2:4531936 | Deinonychus antirrhopus |
| 9 | EOL:4433881 | preysOn | EOL:4518630 | Compsognathus longipes |
How to search by Organism - Sanity check with bats

There are many columns that describe the species or order, you can search by any of the columns. One of the main ways in which researchers would want to use this data is to find the data corresponding to the species or taxa they are interested in. If you want to search for a specific taxa, you can just search using a organism string. I explored this feature a bit to try and understand if the data is making sense i.e. sanity check.
I choose to search a few types of bats and just browse the results to see if they made sense. First off I choose to see what Carollia, a genus of short tail fruit bats, eats.
# Subset by the term Carollia
corollia = data[data['sourceTaxonName'].str.contains('Carollia', na=False)]
#subset by only what Carollia eats
corollia = corollia.loc[corollia.interactionTypeName == 'eats']
# Show only relevant columns
corollia[['sourceTaxonName','sourceTaxonId', 'interactionTypeName', 'targetTaxonName','targetTaxonId']].head(10)
| sourceTaxonName | sourceTaxonId | interactionTypeName | targetTaxonName | targetTaxonId | |
|---|---|---|---|---|---|
| 785626 | Carollia perspicillata | EOL:327438 | eats | Terminalia catappa | GBIF:3189394 |
| 785631 | Carollia perspicillata | EOL:327438 | eats | Terminalia catappa | GBIF:3189394 |
| 785683 | Carollia perspicillata | EOL:327438 | eats | Syzygium malaccense | EOL:2508662 |
| 785688 | Carollia perspicillata | EOL:327438 | eats | Syzygium jambos | EOL:2508661 |
| 785693 | Carollia perspicillata | EOL:327438 | eats | Syzygium jambos | EOL:2508661 |
| 785727 | Carollia perspicillata | EOL:327438 | eats | Syzygium cumini | EOL:2508660 |
| 785900 | Carollia perspicillata | EOL:327438 | eats | Spondias | EOL:61097 |
| 785963 | Carollia perspicillata | EOL:327438 | eats | Solanum | EOL:590245 |
| 785968 | Carollia perspicillata | EOL:327438 | eats | Solanum | EOL:590245 |
| 785970 | Carollia perspicillata | EOL:327438 | eats | Solanum | EOL:590245 |
From above you can see that Carollia perspicillata eats yummy things like Terminalia catappa which is some type of nut and Syzygium malaccense some apple-like fruit. Seems right.

Now lets try another type of bat, Desmodus - the Vampire Bats!
# Subset by the term Desmodus
Desmodus = data[data['sourceTaxonName'].str.contains('Desmodus', na=False)]
#subset by only what Carollia eats or preysOn
Desmodus = Desmodus.loc[(Desmodus.interactionTypeName == 'eats') | (Desmodus.interactionTypeName == 'preysOn')]
# Show only relevant columns
Desmodus[['sourceTaxonName','sourceTaxonId', 'interactionTypeName', 'targetTaxonName','targetTaxonId']].head(10)
| sourceTaxonName | sourceTaxonId | interactionTypeName | targetTaxonName | targetTaxonId | |
|---|---|---|---|---|---|
| 1542376 | Desmodus rotundus | GBIF:2433298 | eats | Bos taurus | GBIF:2441022 |
So if you look up Bos taurus, you see that this animal is “cattle”. A mammal with blood. So creepy. So cool. I highly recommend just trying the above code with
Conclusions
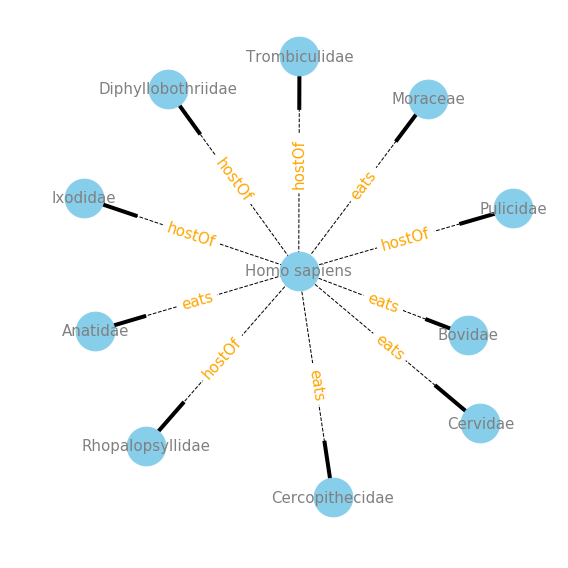
Now that I have a handle on the data I see a few different ways in which to explore the data. If you are like me, and need to google every species or taxa that is in the dataset, you should read next weeks post on automation of hyperlinking species names directly into a Jupyter Notebook, which makes exploring this GLoBI data really intuitive. Also, in the next post I will be creating tools that wrap the interaction data into informative network visualizations. Below is a sneak peak into the type of visualizations I will be creating.